고정 헤더 영역
상세 컨텐츠
본문
* LeNet *
- 성공적으로 convolutional layer를 적용한 첫 번째 모델 (MNIST 데이터 셋 활용)
1) convolution을 통해 channel dimension은 증가시켜줌
2) pooling을 통해 spatial resolution은 줄이고
3) flatten시켜준 후 linear layer에 통과시켜줌
* AlexNet *
- 최초의 딥러닝 모델
- LeNet과 거의 유사한데 convolution layer를 더 깊게 쌓음
* VGGNet *
- 필터는 작은 것을 쓰면서 더 깊게 쌓아줌
- pooling을 통해 (H, W) -> (H/2, W/2)
- convolution을 통해 C -> 2C
- 모든 convolution은 3x3 stride 1 pad 1로 설정
* GoogleNet *
- Inception module을 만들어 쌓음
- Inception module : convolution 필터를 병렬로 처리 후 합치기

- 하지만 naive Inception module을 사용하면 연산이 너무 복잡해짐
- bottleneck layer : 1x1 convolution을 사용해 channel의 크기를 줄여줌
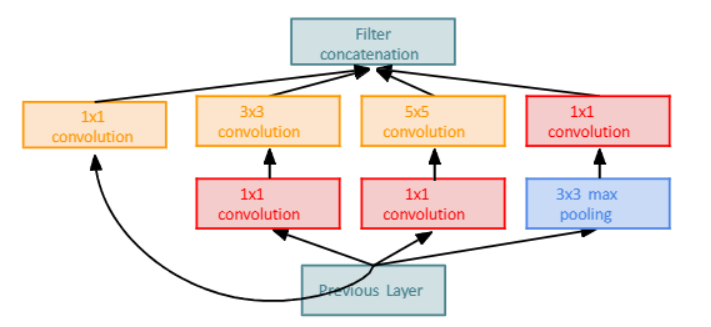
1) Stem Network : Conv-Pool...
2) bottleneck layer를 쌓은 것을 계산
3) linear layer 계산 (중간중간 넣어줌)
- Global average Pooling : linear layer에 넣기 전에 feature map을 일자로 펴 줄 때 사용.
- 그냥 피면 1x1x(CHW)인데 gap를 써주면 1x1xC가 됨
* ResNet *
- layer를 그냥 많이 쌓다보면 학습이 안되는 문제가 생김
- vanishing gradients : 네트워크가 깊어질수록 역전파를 하는동안의 gradient가 너무 작아져서 학습이 안됨
- residual connection(identify mapping) : y = F(x) + x
1) Stem layer
2) residual block을 쌓음
3) 쌓을 때 3x3 conv layer로 해주고
4) 필터의 개수는 2배, spatial dimension은 1/2배
5) 마지막에 global average pooling을 해줌
- ResNet-50 이후로는 계산양을 줄이기 위해 bottleneck residual block을 사용함

* Model Ensemble *
- 모델 여러개 합치기
- 집단 지성 이용
* SeNet *
- feature map의 가중치 재조정
1) GAP를 통해 feature map squeeze (1x1xC)
2) FC layer를 통과해 가중치 예상
3) 가중치 결과를 원래 feature map에 곱함
'인공지능' 카테고리의 다른 글
| Training Neural Network(2) (5) | 2024.12.19 |
|---|---|
| Training Neural Network(1) (3) | 2024.12.18 |
| 인공지능 - Convolution (1) | 2024.10.24 |
| 인공지능 - Optimization(학습) (4) | 2024.10.24 |
| 인공지능 - Loss (2) | 2024.10.24 |




