고정 헤더 영역
상세 컨텐츠
본문
* Sequence to Sequence Model *
- 연속된 데이터를 연속된 데이터로 바꿔주는 모델
- input과 output의 길이는 달라도 됨
- 예) 기계번역, 글 요약
- RNN을 통해 Encoding
- Decoding은 Encoder를 통해 나온 문맥벡터 c를 이용

- sequence가 길어지면 앞쪽의 정보를 반영하기 어려워짐
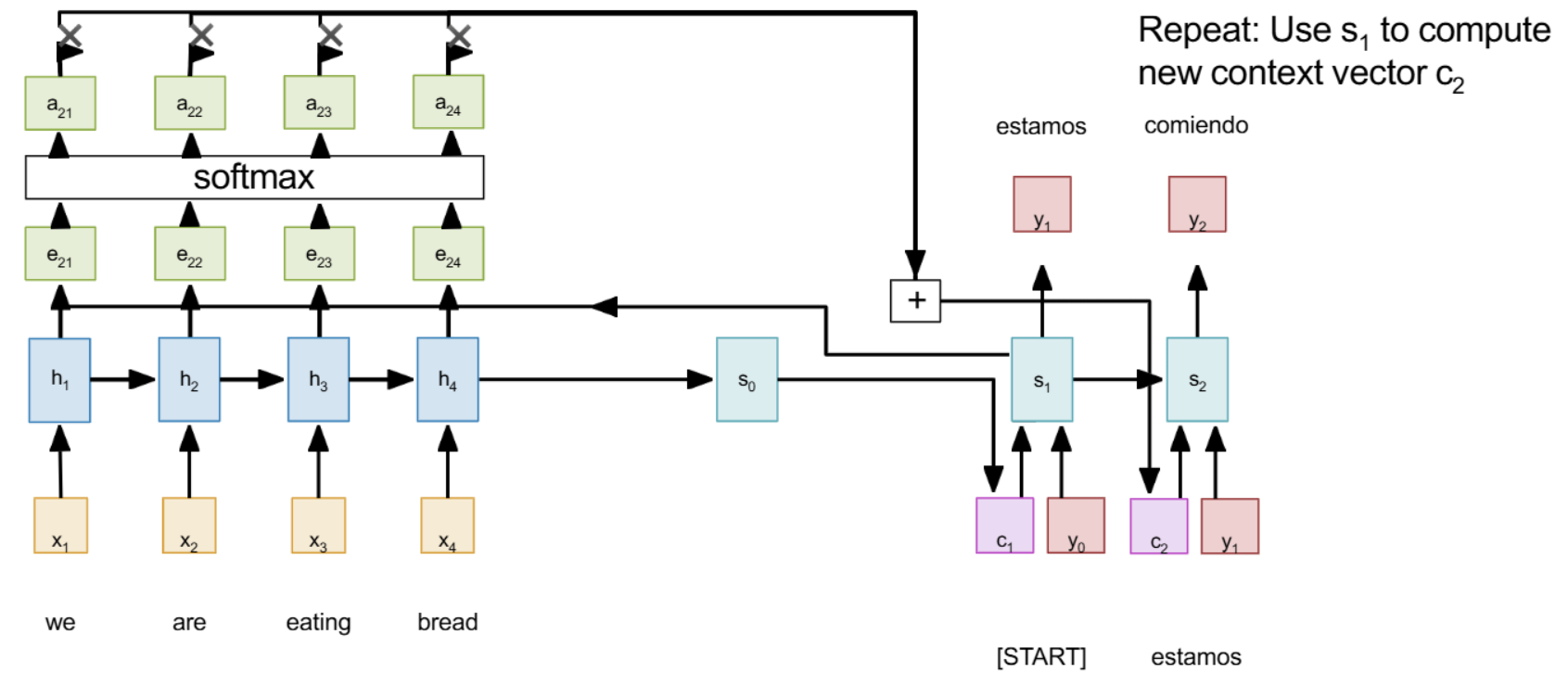
* Attention *
- Decoder의 각 스텝마다 새로운 conext vector를 사용
- Encoder의 마지막 hidden state인 s0과 각 hidden state간의 alignment score를 구한게 e
- e를 소프트맥스 함수에 통과시켜 a를 만듬 (h와 s사이의 가까운 정도를 확률로 표현)
- 그렇게 만들어진 attention을 각 h와 곱해 다 더한 것이 context vector
- 이 과정은 미분가능하므로 backpropagation 가능(학습 가능)
* Image Captioning *
- 인풋은 이미지, 아웃풋은 sequence
1) 이미지를 CNN에 통과해 feature map으로 만들고
2) FC 등을 이용해 하나의 벡터로 만들어줌
3) 그 뒤는 이전 내용과 같음

- 여기에도 attention 적용가능

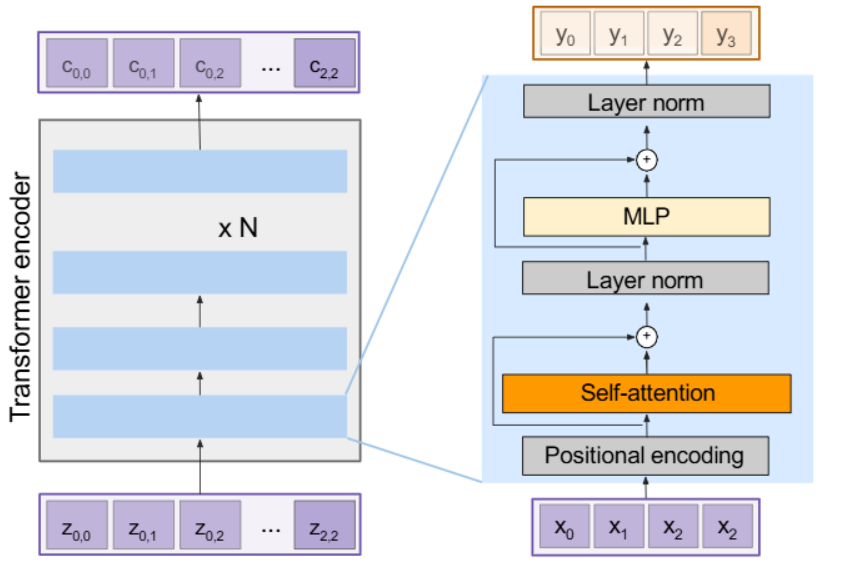
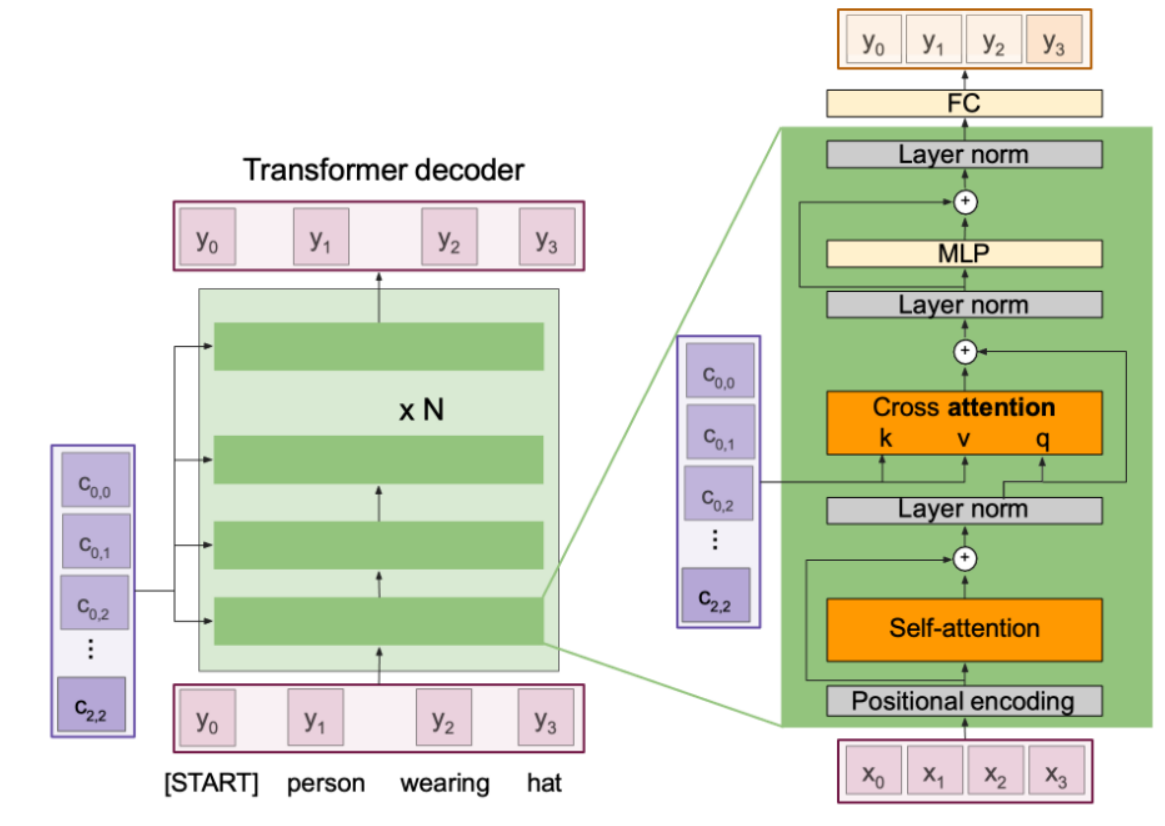
* Transformer *
- 긴 sequence에 좋고, 병렬처리 가능
- Encoder : 차원을 줄임
- Decoder : 차원을 복원
- Attention만으로 모델 구성
- attention layer는 순서에 대한 정보를 고려하지 않으므로 Positional Encoding이 필요
- Self Attention : 인풋을 통해 Query, Key, Value를 만들어줌
- Residual connectio이 사용됨
- Cross Attention : key랑 value는 인코더에서 가져온 것으로, query는 디코더에서 가져온 것으로 만들어줌
- 이미지 캡셔닝에도 트랜스포머 사용 가능
* VIT *
- 이미지 캡셔닝을 CNN없이 오직 트랜스포머만 사용
- 추가 classification 토큰을 추가해줘서 이를 통해 학습 가능
'인공지능' 카테고리의 다른 글
| Image Segmentation and Object Detection (2) | 2024.12.19 |
|---|---|
| Recurrent Neural Network (1) | 2024.12.19 |
| Training Neural Network(2) (5) | 2024.12.19 |
| Training Neural Network(1) (3) | 2024.12.18 |
| Convolutional Neural Network (1) | 2024.12.18 |




