고정 헤더 영역
상세 컨텐츠
본문
1. Ensemble Methods
- 하나의 강력한 모델을 만들기 위해 여러 개의 모델을 결합하는 기법
- 단순하지만 빠르게 학습되는 약한 모델들을 조합해서 더 강력한 모델을 만듬
2. Voting
- 여러 개의 다른 모델의 예측값을 모아서 가장 많이 나온 클래스를 선택하는 방식
- 각 모델의 오류가 서로 독립적이라면 서로의 실수를 보완해 전체 오류율이 줄어듬
3. Stacking
- 단순히 투표하지 않고, 각 모델의 예측을 하나의 새로운 feature로 보고, 그 feature를 입력으로 또 다른 모델을 학습
4. Bagging
- 여러 개의 트리를 부트스트랩된 데이터로 학습시킨 후, 그 예측을 평균해서 최종 예측을 만듬
- 베이스 모델은 하나지만 데이터를 여러개 만듬으로써 각 다른 모델이 나오도록 함
- Bootstrapping : 원본 데이터셋에서 복원 샘플링을 통해 여러 개의 부트스트랩 데이터셋을 만듬
5. Random Forest
- Bagging의 업그레이드 버전으로, 여러개의 트리를 만들고 각각의 트리 결과를 투표해서 결과 도출
- 예측이 매우 빠름
- 결정 트리는 독립적인 오류를 만들지 않음
- Bootstrapping과 Random trees를 사용
- Random trees: 각 트리를 만들 때, 노드 분할을 위해 특성 중 랜덤하게 일부만 선택해 학습
- 이로인해 트리들이 서로 다르게 학습됨(model의 variation)

- 원본 데이터셋 (X, y)로부터 여러 개의 부트스트랩 샘플을 생성
- 각 샘플은 중복이 있을 수 있고 없는 샘플도 있을 수 있음
- 각각의 부트스트랩 샘플로 하나의 결정트리를 학습
- 각 모델은 서로 다른 데이터로 학습되고, 트리의 구조도 random feature selection 때문에 다름
- 최종 예측은 다수결에 따라 결정
- 부트스트랩 샘플이 오류를 독립적으로 발생하도록 함
6. Boosting
- 같은 종류의 약한 분류기를 반복해서 학습시키되, 매번 학습 데이터의 가중치를 조절하고 최종적으로 투표함
- 잘못 분류된 샘플에는 더 높은 가중치를 부여하여 다음 모델이 그 샘플에 더 집중하도록 유도
- 최종 분류기는 아래처럼 모든 분류기의 가중 합으로 결정
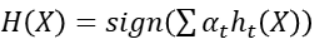
1) AdaBoost: 여러 약한 분류기를 조합해 강력한 최종 분류기를 만드는 부스팅 기법중 하나
- 초기화 시에는 모든 샘플의 가중치를 균등하게 설정 wᵢ = 1/N

2) XGBoost: 회귀 트리를 사용하며 각 리프는 실수 값 예측을 제공
- 예측 오차를 점점 줄여가는 방식으로 학습
- 최종 예측은 모든 트리의 예측값을 단순히 더해서 얻음
- 정규화도 수행하는데 L1, L2 사용
- 또는 전체 트리를 먼저 성장시킨 다음 L1 정규화를 이용해 불필요한 가지를 후처리로 제거
'머신러닝' 카테고리의 다른 글
| SVM (0) | 2025.04.20 |
|---|---|
| Regularization (0) | 2025.04.19 |
| Generalization (0) | 2025.04.19 |
| Regression(2) (0) | 2025.04.18 |
| Regression (0) | 2025.04.18 |




